

شرکت ها از داده های رسانه های اجتماعی برای آموزش مدل های هوش مصنوعی استفاده می کنند و می فروشند. کاربر معمولی شبکه های اجتماعی چه کاری می تواند در مورد آن انجام دهد؟
پلتفرمهای رسانههای اجتماعی، علیرغم نگرانیهای مربوط به حفظ حریم خصوصی، دادههای کاربران را برای آموزش مدلهای هوش مصنوعی مولد به شرکتهای هوش مصنوعی میفروشند.
- پلتفرم هایی مانند Meta، Reddit، Tumblr و WordPress.com به طور فعال در این معاملات مجوز داده برای آموزش هوش مصنوعی درگیر هستند.
- کاربران میتوانند برای محافظت از دادههای خود اقدامات کوچکی انجام دهند، مانند تنظیم تنظیمات حریم خصوصی، انصراف از اشتراک گذاری، و محتاط بودن در مورد آنچه که به صورت آنلاین پست میکنند.
یکی از جدیدترین روشهایی که شرکتهای رسانههای اجتماعی از دادههای کاربران کسب درآمد میکنند، معامله با شرکتهای هوش مصنوعی است. اما آیا کاربران عادی می توانند برای محافظت از داده ها و محتوای خود کاری انجام دهند؟
پلتفرم های رسانه های اجتماعی با شرکت های هوش مصنوعی معامله می کنند
استفاده از دادههای رسانههای اجتماعی برای آموزش مدلهای هوش مصنوعی مولد یک حرکت بحث برانگیز بوده است، اما به نظر نمیرسد که این مانع از توزیع دادههای کاربران توسط شرکتهای رسانههای اجتماعی نمی شود.
Meta در حال حاضر از دادههای رسانههای اجتماعی برای آموزش ویژگیهای هوش مصنوعی مولد اعلامشده در Meta Connect در سال ۲۰۲۳ استفاده می کند. این شامل هوش مصنوعی متا و ویژگیهایی مانند ایجاد برچسبهای تولید شده توسط هوش مصنوعی در واتساپ است.
همانطور که مایک کلارک، مدیر مدیریت محصول در متا در پست اتاق خبر متا اظهار داشت:
به نظر نمی رسد این روند در سال 2024 کاهش یابد. به گزارش رویترز، Reddit با گوگل به توافقی دست یافت تا محتوای پلتفرم رسانه های اجتماعی را برای آموزش مدل های هوش مصنوعی در دسترس قرار دهد.
پرونده S-1 Reddit برای IPO خود، که در 22 فوریه 2024 ثبت شد، تأیید می کند که این شرکت در حال بررسی معاملات مجوز می باشد. در پرونده آمده است:
مشخص می کند که Reddit “در مراحل اولیه اجازه دادن به اشخاص ثالث برای دسترسی به جستجو، تجزیه و تحلیل و نمایش داده های تاریخی و بلادرنگ از پلتفرم ما” به منظور آموزش LLM است.
و در حالی که Meta و Reddit برخی از بزرگ ترین نامها در رسانههای اجتماعی هستند، آنها تنها پلتفرمهایی نیستند که از دادههای رسانههای اجتماعی برای آموزش هوش مصنوعی استفاده می کنند. طبق گزارش 404 Media، Tumblr و WordPress.com در حال آماده شدن برای فروش داده های کاربران به Midjourney و OpenAI هستند.
آیا می توانید پلتفرم ها را از فروش داده های رسانه های اجتماعی خود برای آموزش هوش مصنوعی منع کنید؟
این احتمال وجود دارد که اگر از Facebook، Instagram، Reddit، Tumblr یا WordPress.com استفاده میکنید، از محتوای عمومی شما قبلاً در آموزش LLM استفاده شده است.
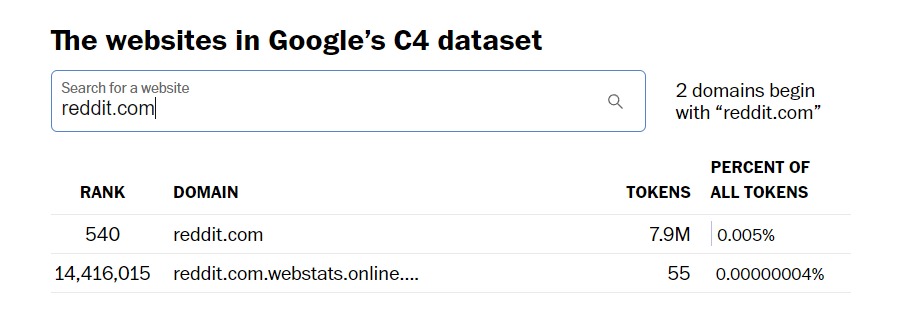
به عنوان مثال، اگر از ابزار جستجوی واشنگتن پست استفاده کنید تا ببینید چه سایت هایی در مجموعه داده های C4 گوگل که به عنوان بخشی از آموزش بارد استفاده می شد، گنجانده شده است، خواهید دید که Reddit.com 7.9 میلیون توکن دارد.
Tumblr.com دارای 1.6 میلیون توکن است. وب سایت کوچک ما که از WordPress.com استفاده میکند، 14000 توکن دارد—بنابراین وبلاگهای شخصی کوچک ممکن است در مجموعه داده گنجانده شده باشند.
با معاملات مداوم بین شرکتهای هوش مصنوعی و شرکتهای رسانههای اجتماعی، معاملات مجوز به این معنی است که این دادهها بهجای حذف شدن از وب، فعالانه فروخته میشوند.
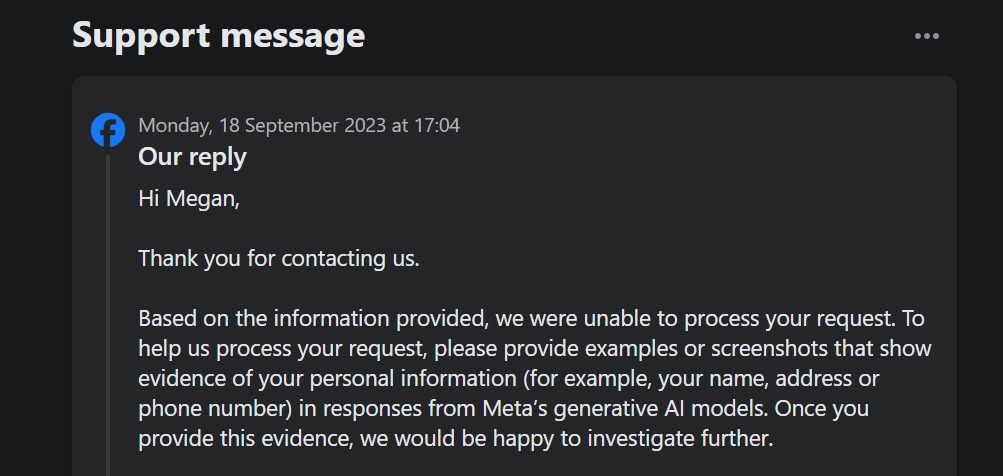
اما وقتی نوبت به پردازش آینده می رسد، چه کاری می توانید انجام دهید؟ متا فرمی را برای حقوق موضوع داده های هوش مصنوعی مولد معرفی کرده که به شما امکان می دهد برای آموزش مدل های هوش مصنوعی متا به پردازش داده های شخصی خود از اشخاص ثالث اعتراض یا محدود کنید.
قابل ذکر است، این گزینه به شما اجازه نمی دهد که به پردازش شخص اول متا از داده های شما برای آموزش هوش مصنوعی مولد اعتراض کنید. علاوه بر این، هنگامی که ما یک بلیط برای اعتراض به استفاده از داده های شخصی خود با استفاده از فرم ارسال کردیم، بلیط پشتیبانی از ما می خواست ثابت کنیم که اطلاعات شخصی ما قبلاً در نتایج هوش مصنوعی متا ظاهر گردیده.
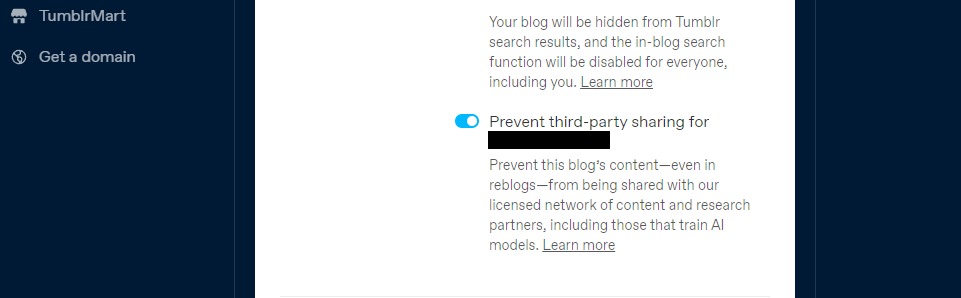
Tumblr همچنین گزینه ای را برای انصراف از اشتراک گذاری محتوای وبلاگ های عمومی شما با اشخاص ثالث با استفاده از تنظیمات وبلاگ شما معرفی کرده است. با کلیک بر روی وبلاگ خود و پایین رفتن به تنظیمات Visibility می توانید آن را در تنظیمات خود پیدا کنید. سپس گزینه جلوگیری از اشتراک گذاری شخص ثالث برای وبلاگ خود را انتخاب نمایید.
وقتی صحبت از پلتفرمی مانند اینستاگرام می شود، می توانید سعی کنید اکانت اینستاگرام خود را به خصوصی تغییر دهید تا از استفاده از داده های خود جلوگیری کنید. این تضمین نمیکند که از دادههای شما استفاده نمیشود، اما از آنجایی که به نظر میرسد حذف دادهها برای LLM بر روی دادههای عمومی تمرکز دارد، میتواند یک حفاظت بالقوه باشد.
همچنین میتوانید اکانت X (توئیتر) خود را خصوصی کنید، اما بار دیگر این فقط یک حفاظت بالقوه است و تضمین نمیکند که دادههای شما خصوصی باقی بماند.
بیانیه مشترک کمیسیونرها و کارشناسان اطلاعات ملی مختلف در سراسر جهان، همچنین اقداماتی را برای افرادی که به دنبال به حداقل رساندن خطر حفظ حریم خصوصی ناشی از حذف داده ها توسط شرکت های هوش مصنوعی هستند، پیشنهاد کرده است. مشاوره شامل:
- شرایط و سیاست حفظ حریم خصوصی یک وب سایت را بخوانید تا ببینید چگونه اطلاعات شخصی شما را به اشتراک می گذارد.
- اطلاعاتی را که به صورت آنلاین پست می کنید، به خصوص اطلاعات حساس را محدود نمایید.
- تنظیمات حریم خصوصی خود را مدیریت کنید.
- در مورد اطلاعاتی که به صورت آنلاین به اشتراک می گذارید درازمدت فکر کنید.
- اگر فکر می کنید اطلاعات شما پاک شده است، با شرکت رسانه اجتماعی یا وب سایت تماس بگیرید. اگر از پاسخ آنها ناراضی هستید، به مرجع حفاظت از داده مربوطه خود رفته و شکایت کنید.
همچنین اگر دسترسی اشخاص ثالث به آن راحت نیست، میتوانید اطلاعات خاصی را به صورت آنلاین حذف کنید، اگرچه ممکن است اطلاعات عمومی موجود در پروفایل های شما قبلاً حذف شده باشد.
متأسفانه، ما به عنوان کاربران معمولی می توانیم کارهای زیادی برای محافظت از داده های خود در برابر شرکت های هوش مصنوعی انجام دهیم. کنترل واقعی بر این اطلاعات احتمالاً تنها با کمک تنظیمکنندهها خواهد بود.







