

به عنوان یک متخصص سئو، در مورد ChatGPT و BARD شنیده اید – یا حتی خودتان از آنها استفاده کرده اید. یادگیری ماشین در دنیای واقعی را در ادامه بررسی کرده ایم.
همچنین ممکن است با تعداد انگشت شماری از مدل های یادگیری ماشین گوگل مانند BERT و RankBrain آشنا باشید.
اینها همه کاربردهای عالی یادگیری ماشین هستند.
اما همیشه بلافاصله مشخص نیست که چگونه یادگیری ماشینی می تواند برای وظایف BAU (کسب و کار معمول) یا کارهای روزانه SEO مفید باشد.
همچنین در مورد استفاده از یادگیری ماشینی در کارتان، مانند حفظ حریم خصوصی و انصاف داده ها، مسئله اخلاق نیز وجود دارد.
با این حال، درک اینکه چگونه یادگیری ماشین در جستجو (و در زندگی واقعی) کار میکند، فقط میتواند به نفع شما به عنوان یک متخصص سئو کار کند – چه فنی باشید یا نه.
در این مقاله جامع، انواع یادگیری ماشینی و اصول اخلاقی مرتبط با این فناوری را بیاموزید، سپس از هفت نمونه یادگیری ماشینی الهام بگیرید که تاثیر زیادی بر دنیای ما داشته است.
یادگیری ماشینی چیست؟
یادگیری ماشینی زیرمجموعهای از هوش مصنوعی (AI) است که سیستمها را قادر میسازد بدون نیاز به برنامهریزی صریح، یاد بگیرند و پیشرفت کنند. این امر با استفاده از مجموعه داده های بزرگی که پارامترها را در مدل آموزش می دهند به دست می آید.
شاید شناختهشدهترین نمونههای یادگیری ماشین در حال حاضر ChatGPT و BARD باشند – و در حالی که این پست روی آنها تمرکز نخواهد کرد، تصمیم گرفتم از هر دو بخواهم که برای من توضیح دهند که یادگیری ماشین چیست. در اینجا پاسخ آنها است:
ChatGPT
یادگیری ماشینی نوعی هوش مصنوعی است که به نرم افزارهای کاربردی اجازه می دهد تا از داده ها یاد بگیرند و در پیش بینی نتایج بدون برنامه ریزی صریح دقیق تر شوند. به عبارت دیگر، این روشی است برای آموزش کامپیوترها برای یادگیری از داده هایی که به آنها داده می شود و سپس تصمیم گیری یا پیش بینی بر اساس آن یادگیری.
هدف یادگیری ماشینی توسعه الگوریتم هایی است که بتوانند الگوهای موجود در داده ها را یاد بگیرند و سپس از آن الگوها برای تصمیم گیری یا پیش بینی در مورد داده های جدید استفاده کنند. این کار با آموزش الگوریتم یادگیری ماشین بر روی مجموعه داده ای از ورودی ها و خروجی های شناخته شده و سپس استفاده از آن دانش برای پیش بینی داده های جدید و نادیده انجام می شود.
برخی از کاربردهای رایج یادگیری ماشینی عبارتند از: تشخیص تصویر، پردازش زبان طبیعی، تشخیص تقلب و سیستمهای توصیه.
BARD
“یادگیری ماشینی مطالعه الگوریتم های کامپیوتری است که به طور خودکار از طریق تجربه و با استفاده از داده ها بهبود می یابند. به عنوان زیر مجموعه ای از هوش مصنوعی دیده می شود. الگوریتمهای یادگیری ماشینی مدلی را بر اساس دادههای نمونه میسازند که به دادههای آموزشی معروف است، تا بدون برنامهریزی صریح، پیشبینی یا تصمیمگیری کنند.
یادگیری ماشینی می تواند برای کارهای مختلفی استفاده شود، از جمله:
طبقه بندی: مرتب سازی داده ها به دسته ها. به عنوان مثال، یک فیلتر هرزنامه ممکن است ایمیل ها را به عنوان هرزنامه یا غیر هرزنامه طبقه بندی کند.
رگرسیون: پیش بینی یک مقدار پیوسته. به عنوان مثال، پیش بینی آب و هوا ممکن است دمای فردا را پیش بینی کند.
خوشه بندی: گروه بندی نقاط داده با هم بر اساس شباهت آنها. به عنوان مثال، یک سیستم توصیهگر ممکن است کاربران را بر اساس خریدهای قبلی خود دستهبندی کند.
تشخیص ناهنجاری: شناسایی نقاط داده غیرمعمول. به عنوان مثال، یک سیستم تشخیص تقلب ممکن است تراکنش هایی را که احتمالاً تقلبی هستند شناسایی کند.
یادگیری ماشینی ابزار قدرتمندی است که میتوان از آن برای حل مشکلات مختلف استفاده کرد. با این حال، توجه به این نکته مهم است که الگوریتمهای یادگیری ماشین تنها به اندازه دادههایی هستند که روی آنها آموزش دیدهاند. اگر داده ها بایاس باشند، الگوریتم نیز بایاس می شود. علاوه بر این، الگوریتمهای یادگیری ماشینی میتوانند مستعد بیش از حد برازش باشند، یعنی زمانی که الگوریتم دادههای آموزشی را خیلی خوب یاد میگیرد و به خوبی به دادههای جدید تعمیم نمییابد.
با وجود این چالش ها، یادگیری ماشین یک زمینه به سرعت در حال رشد با طیف گسترده ای از برنامه ها است. از آنجایی که میزان داده های موجود در دسترس ما همچنان در حال رشد است، احتمالاً یادگیری ماشینی نقش مهم تری در زندگی ما در آینده ایفا خواهد کرد.”
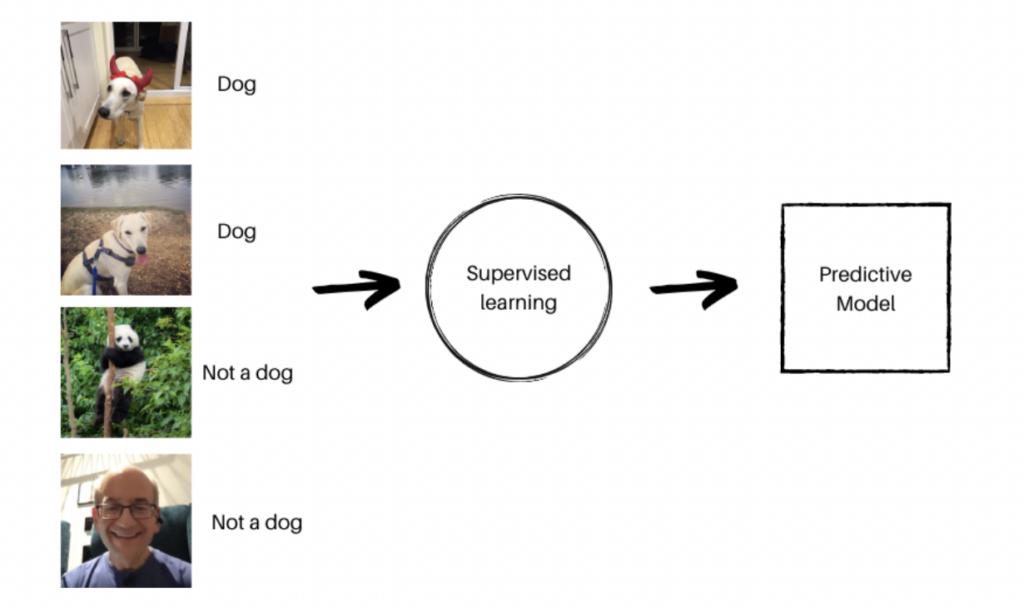
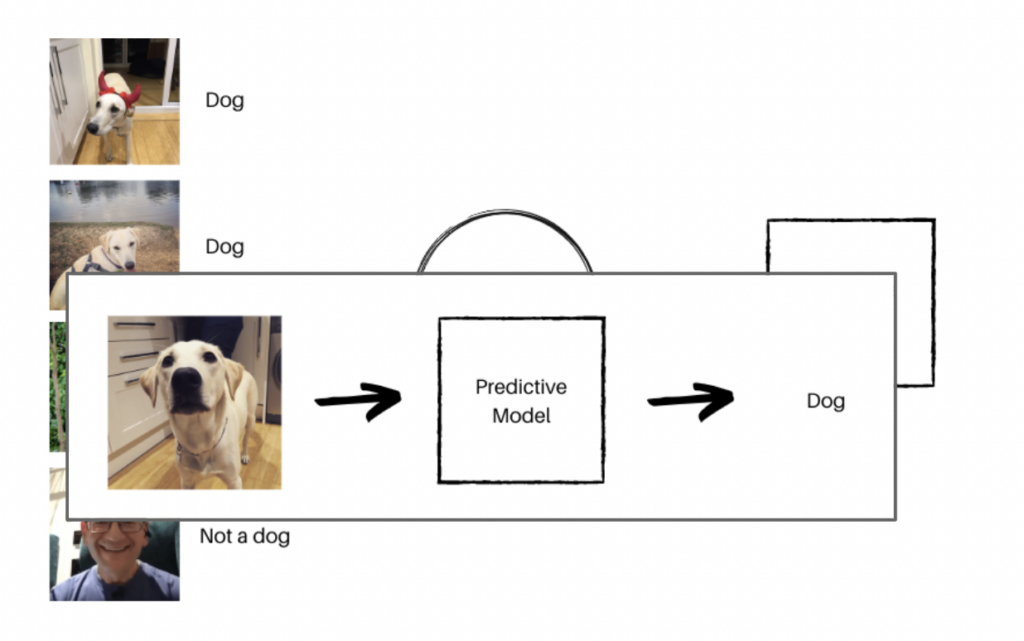
یادگیری تحت نظارت
همانطور که از نام آن پیداست، در یادگیری تحت نظارت، مدل تحت نظارت یاد می گیرد. با داده های برچسب دار آموزش داده می شود و خروجی به صورت دستی بررسی می شود.
ماشین از دادههای برچسبگذاری شده یاد میگیرد و سپس برای پیشبینیهای آینده استفاده میشود.
پس از دریافت خروجی، مدل آن را به خاطر می آورد و برای عملیات بعدی از آن استفاده می کند.
دو نوع اصلی یادگیری تحت نظارت وجود دارد: طبقه بندی و رگرسیون.
طبقه بندی
طبقه بندی زمانی است که متغیر خروجی دارای دو یا چند کلاس است که مدل می تواند آنها را شناسایی کند. مثلاً درست یا غلط و سگ یا گربه.
نمونههایی از این موارد شامل پیشبینی اینکه آیا ایمیلها احتمالاً اسپم هستند یا تصویری از سگ یا گربه است.
در هر دوی این مثالها، مدل بر روی دادههایی که به عنوان هرزنامه یا غیر هرزنامه طبقهبندی میشوند و اینکه آیا یک تصویر حاوی سگ یا گربه است آموزش داده میشود.
پس رفت
این زمانی است که متغیر خروجی یک مقدار واقعی یا پیوسته است و بین متغیرها رابطه وجود دارد. اساساً تغییر در یک متغیر با تغییری که در متغیر دیگر رخ می دهد همراه است.
سپس مدل رابطه بین آنها را یاد می گیرد و بسته به داده هایی که داده می شود، نتیجه را پیش بینی می کند.
به عنوان مثال، پیش بینی رطوبت بر اساس یک مقدار دمای معین یا اینکه قیمت سهام احتمالاً در یک زمان معین چه خواهد بود.
یادگیری بدون نظارت
یادگیری بدون نظارت زمانی است که مدل از داده های بدون برچسب استفاده می کند و به تنهایی و بدون هیچ نظارتی یاد می گیرد. اساسا، بر خلاف یادگیری نظارت شده، مدل بدون هیچ راهنمایی روی داده های ورودی عمل می کند.
نیازی به داده های برچسب دار ندارد، زیرا وظیفه آن جستجوی الگوها یا ساختارهای پنهان در داده های ورودی و سپس سازماندهی آن بر اساس شباهت ها و تفاوت ها است.
به عنوان مثال، اگر به مدلی تصاویری از سگ و گربه داده شود، قبلاً برای دانستن ویژگیهایی که هر دو را متمایز میکند، آموزش ندیده است. با این حال، می تواند آنها را بر اساس الگوهای شباهت ها و تفاوت ها دسته بندی کند.
همچنین دو نوع اصلی یادگیری بدون نظارت وجود دارد: خوشه بندی و تداعی.
دسته بندی/خوشه بندی
خوشهبندی روش مرتبسازی اشیا به خوشههایی است که شبیه یکدیگر و متعلق به یک خوشه هستند، در مقابل اشیایی که به یک خوشه خاص شباهت ندارند و بنابراین به خوشه دیگری تعلق دارند.
نمونه هایی از این موارد شامل سیستم های توصیه و طبقه بندی تصویر است.
اتحادیه
ارتباط مبتنی بر قانون است و برای کشف احتمال وقوع همزمان موارد در مجموعه ای از مقادیر استفاده می شود.
به عنوان مثال می توان به کشف تقلب، تقسیم بندی مشتری و کشف عادات خرید اشاره کرد.
یادگیری نیمه نظارتی
یادگیری نیمه نظارتی با استفاده از بخش کوچکی از داده های برچسب دار، همراه با داده های بدون برچسب، برای آموزش مدل، هم یادگیری تحت نظارت و هم بدون نظارت را پل می کند. بنابراین، برای مشکلات مختلف، از طبقهبندی و رگرسیون گرفته تا خوشهبندی و تداعی، کار میکند.
اگر مقدار زیادی داده بدون برچسب وجود داشته باشد، می توان از یادگیری نیمه نظارتی استفاده کرد، زیرا فقط به بخش کوچکی از داده ها نیاز دارد تا برای آموزش مدل برچسب گذاری شود، که سپس می تواند روی داده های بدون برچسب باقی مانده اعمال شود.
Google از یادگیری نیمه نظارتی برای درک بهتر زبان مورد استفاده در جستجو استفاده کرده است تا اطمینان حاصل کند که مرتبط ترین محتوا را برای یک جستجوی خاص ارائه می دهد.
یادگیری تقویتی
یادگیری تقویتی زمانی است که یک مدل آموزش داده می شود تا با اتخاذ رویکردی متوالی در تصمیم گیری، راه حل بهینه را برای یک مسئله بازگرداند.
از آزمون و خطا از تجربیات خود برای تعریف خروجی استفاده میکند و اگر برای رسیدن به هدف کار نمیکند، پاداش برای رفتار مثبت و تقویت منفی میدهد.
این مدل با محیطی که راه اندازی شده است در تعامل است و راه حل هایی را بدون دخالت انسان ارائه می کند.
سپس دخالت انسان برای ارائه تقویت مثبت یا منفی بسته به میزان نزدیک بودن خروجی به هدف معرفی خواهد شد.
به عنوان مثال می توان به روباتیک – فکر کنید ربات هایی که در خط مونتاژ کارخانه کار می کنند – و بازی، با AlphaGo به عنوان معروف ترین نمونه، اشاره کرد. اینجاست که این مدل برای شکست دادن قهرمان AlphaGo با استفاده از یادگیری تقویتی برای تعریف بهترین رویکرد برای برنده شدن در بازی آموزش داده شد.
اخلاق یادگیری ماشین
شکی نیست که یادگیری ماشین مزایای زیادی دارد و استفاده از مدل های یادگیری ماشینی روز به روز در حال رشد است.
با این حال، در نظر گرفتن نگرانی های اخلاقی ناشی از استفاده از این نوع فناوری مهم است. این نگرانی ها عبارتند از:
دقت مدل یادگیری ماشینی و اینکه آیا خروجی درستی ایجاد می کند یا خیر.
سوگیری در دادههایی که برای آموزش مدلها استفاده میشود، که باعث سوگیری در خود مدل و در نتیجه سوگیری در نتیجه میشود. اگر سوگیری تاریخی در دادهها وجود داشته باشد، این سوگیری اغلب در سرتاسر تکرار میشود.
انصاف در نتایج و روند کلی.
حریم خصوصی – به ویژه با داده هایی که برای آموزش مدل های یادگیری ماشین استفاده می شود – و همچنین دقت نتایج و پیش بینی ها.
7 مثال یادگیری ماشین در دنیای واقعی
Netflix
نتفلیکس از یادگیری ماشینی به روش های مختلفی استفاده می کند تا بهترین تجربه را برای کاربران خود فراهم کند.
این شرکت همچنین به طور مداوم در حال جمعآوری مقادیر زیادی از دادهها، از جمله رتبهبندی، موقعیت مکانی کاربران، مدت زمانی است که چیزی در آن تماشا میشود، اگر محتوا به فهرست اضافه شود، و حتی اینکه آیا چیزی بهصورت بیسابقه تماشا شده است یا خیر.
سپس از این داده ها برای بهبود بیشتر مدل های یادگیری ماشین استفاده می شود.
توصیه های محتوا
توصیه های تلویزیونی و فیلم در Netflix بر اساس ترجیحات هر کاربر شخصی سازی شده است. برای انجام این کار، نتفلیکس سیستم توصیهای را راهاندازی کرد که محتوای مصرفشده قبلی، ژانرهای پربازدید کاربران و محتوای تماشا شده توسط کاربران با اولویتهای مشابه را در نظر میگیرد.
تصاویر کوچک تولید شده به صورت خودکار
نتفلیکس کشف کرد که تصاویر استفاده شده در صفحه مرورگر تفاوت زیادی در تماشای یا عدم تماشای چیزی توسط کاربران ایجاد می کند.
بنابراین، از یادگیری ماشین برای ایجاد و نمایش تصاویر مختلف با توجه به ترجیحات فردی کاربر استفاده می کند. این کار این کار را با تجزیه و تحلیل انتخابهای محتوای قبلی کاربر و یادگیری نوع تصویری انجام میدهد که احتمالاً آنها را تشویق به کلیک کردن میکند.
اینها فقط دو نمونه از نحوه استفاده نتفلیکس از یادگیری ماشینی در پلتفرم خود هستند. اگر می خواهید در مورد نحوه استفاده از آن بیشتر بدانید، می توانید وبلاگ حوزه های تحقیقاتی شرکت را بررسی کنید.
Airbnb
با میلیونها فهرست در مکانهای مختلف در سراسر جهان با قیمتهای مختلف، Airbnb از یادگیری ماشینی استفاده میکند تا اطمینان حاصل کند که کاربران میتوانند به سرعت آنچه را که به دنبال آن هستند پیدا کنند و تبدیلها را بهبود بخشد.
روشهای مختلفی وجود دارد که شرکت یادگیری ماشینی را به کار میگیرد و جزئیات زیادی را در وبلاگ مهندسی خود به اشتراک میگذارد.
طبقه بندی تصویر
از آنجایی که میزبان ها می توانند تصاویر دارایی خود را آپلود کنند، Airbnb متوجه شد که بسیاری از تصاویر دارای برچسب اشتباه هستند. برای بهینهسازی تجربه کاربر، یک مدل طبقهبندی تصویر را به کار برد که از دید کامپیوتری و یادگیری عمیق استفاده میکرد.
هدف این پروژه دسته بندی عکس ها بر اساس اتاق های مختلف بود. این امر به Airbnb امکان میدهد تا تصاویر فهرستشده را براساس نوع اتاق نشان دهد و مطمئن شود که فهرست از دستورالعملهای Airbnb پیروی میکند.
برای انجام این کار، شبکه عصبی طبقهبندی تصاویر ResNet50 را با تعداد کمی عکس برچسبگذاری شده مجدداً آموزش داد. این به آن امکان داد تا تصاویر فعلی و آینده آپلود شده در سایت را به دقت طبقه بندی کند.
رتبه بندی جستجو
برای ارائه یک تجربه شخصی برای کاربران، Airbnb یک مدل رتبه بندی را به کار گرفته است که جستجو و کشف را بهینه می کند. دادههای این مدل از معیارهای تعامل کاربر مانند کلیکها و رزروها به دست آمده است.
فهرستها با سفارشدهی تصادفی شروع شدند و سپس عوامل مختلفی در مدل وزن داده شدند – از جمله قیمت، کیفیت و محبوبیت در بین کاربران. هر چه یک لیست وزن بیشتری داشته باشد، در لیست ها بیشتر نمایش داده می شود.
از آن زمان این بهینه سازی شده است، با داده های آموزشی از جمله تعداد مهمانان، قیمت، و در دسترس بودن نیز در مدل گنجانده شده است تا الگوها و اولویت ها را برای ایجاد تجربه شخصی تر کشف کنید.
Spotify
Spotify همچنین از چندین مدل یادگیری ماشینی برای ادامه انقلابی در نحوه کشف و مصرف محتوای صوتی استفاده می کند.
توصیه ها
Spotify از یک الگوریتم توصیه استفاده می کند که اولویت کاربر را بر اساس مجموعه ای از داده های سایر کاربران پیش بینی می کند. این به دلیل شباهتهای متعددی است که بین انواع موسیقی که گروههایی از مردم به آن گوش میدهند، رخ میدهد.
لیست های پخش یکی از راه هایی است که می تواند این کار را انجام دهد، استفاده از روش های آماری برای ایجاد لیست های پخش شخصی برای کاربران، مانند Discover Weekly و میکس های روزانه.
سپس میتواند از دادههای بیشتری برای تنظیم آنها بسته به رفتار کاربر استفاده کند.
با وجود میلیون ها لیست پخش شخصی، Spotify دارای پایگاه داده عظیمی برای کار است – به خصوص اگر آهنگ ها گروه بندی شده و با معنای معنایی برچسب گذاری شوند.
این به این شرکت اجازه داده است تا آهنگ هایی را به کاربرانی با سلیقه موسیقی مشابه توصیه کند. مدل یادگیری ماشینی میتواند آهنگهایی را برای کاربرانی با سابقه شنیداری مشابه ارائه کند تا به کشف موسیقی کمک کند.
زبان طبیعی
با الگوریتم زبان پردازش طبیعی (NLP) که رایانهها را قادر میسازد متن را بهتر از همیشه درک کنند، Spotify میتواند موسیقی را بر اساس زبان مورد استفاده برای توصیف آن دستهبندی کند.
می تواند وب را برای متن روی یک آهنگ خاص خراش دهد و سپس از NLP برای دسته بندی آهنگ ها بر اساس این زمینه استفاده کند.
این همچنین به الگوریتمها کمک میکند آهنگها یا هنرمندانی را که به لیستهای پخش مشابه تعلق دارند شناسایی کنند، که به سیستم توصیه بیشتر کمک میکند.
Detecting Fake News
در حالی که ابزارهای هوش مصنوعی مانند تولید محتوای یادگیری ماشینی میتوانند منبعی برای ایجاد اخبار جعلی باشند، مدلهای یادگیری ماشینی که از پردازش زبان طبیعی استفاده میکنند نیز میتوانند برای ارزیابی مقالات و تعیین اینکه آیا حاوی اطلاعات نادرست هستند، استفاده شوند.
پلتفرمهای شبکههای اجتماعی از یادگیری ماشینی برای یافتن کلمات و الگوهایی در محتوای به اشتراکگذاشتهشده استفاده میکنند که میتواند نشاندهنده اشتراکگذاری اخبار جعلی باشد و آن را بهطور مناسب پرچمگذاری کند.
Health Detection
نمونه ای از یک شبکه عصبی وجود دارد که بر روی بیش از 100000 تصویر آموزش داده شده است تا ضایعات پوستی خطرناک را از ضایعات خوش خیم تشخیص دهد. هنگامی که این مدل بر روی متخصصان پوست انسان آزمایش شد، میتوان 95 درصد سرطان پوست را از روی تصاویر ارائهشده به دقت تشخیص داد، در مقایسه با 86.6 درصد توسط متخصصان پوست.
از آنجایی که مدل ملانوم کمتری را از دست داد، مشخص شد که حساسیت بالاتری دارد و به طور مداوم در طول فرآیند آموزش داده میشود.
این امید وجود دارد که یادگیری ماشین و هوش مصنوعی، همراه با هوش انسانی، ممکن است به ابزار مفیدی برای تشخیص سریعتر تبدیل شوند.
روشهای دیگری که تشخیص تصویر در مراقبتهای بهداشتی استفاده میشود عبارتند از شناسایی ناهنجاریها در اشعه ایکس یا اسکن و شناسایی نشانههای کلیدی که ممکن است نشان دهنده یک بیماری زمینهای باشد.
Wildlife Security
Protection Assistant for Wildlife Security یک سیستم هوش مصنوعی است که برای ارزیابی اطلاعات مربوط به فعالیت های شکار غیرقانونی استفاده می شود تا یک مسیر گشت زنی برای محیط بانان ایجاد کند تا از حملات شکار غیرقانونی جلوگیری کند.
این سیستم به طور مداوم با داده های بیشتری مانند مکان تله ها و مشاهده حیوانات ارائه می شود که به هوشمندتر شدن آن کمک می کند.
تجزیه و تحلیل پیشبینیکننده، واحدهای گشت را قادر میسازد تا مناطقی را که احتمال دارد شکارچیان غیرقانونی حیوانات از آنجا بازدید کنند، شناسایی کنند.
8 مثال یادگیری ماشین در سئو
کیفیت محتوا
مدلهای یادگیری ماشینی را میتوان برای بهبود کیفیت محتوای وبسایت با پیشبینی آنچه که کاربران و موتورهای جستجو ترجیح میدهند ببینند، آموزش داد.
این مدل را می توان در مورد مهم ترین بینش ها، از جمله حجم جستجو و ترافیک، نرخ تبدیل، لینک های داخلی و تعداد کلمات آموزش داد.
سپس میتوان برای هر صفحه یک امتیاز کیفیت محتوا ایجاد کرد، که به اطلاع رسانی در مورد بهینهسازیها کمک میکند و میتواند به ویژه برای ممیزی محتوا مفید باشد.
پردازش زبان طبیعی
پردازش زبان طبیعی (NLP) از یادگیری ماشینی برای آشکار کردن ساختار و معنای متن استفاده می کند. متن را برای درک احساسات و استخراج اطلاعات کلیدی تجزیه و تحلیل می کند.
NLP به جای کلمات بر درک زمینه تمرکز دارد. این بیشتر به محتوای پیرامون کلمات کلیدی و نحوه قرار گرفتن آنها در جملات و پاراگراف ها مربوط می شود تا کلمات کلیدی به تنهایی.
احساسات کلی نیز در نظر گرفته می شود، زیرا به احساس پشت جستجوی جستجو اشاره دارد. انواع کلمات مورد استفاده در جستجو کمک می کند تا مشخص شود که آیا این جستجو به عنوان دارای احساسات مثبت، منفی یا خنثی طبقه بندی می شود.
حوزه های کلیدی مهم برای NLP عبارتند از:
موجودیت – کلماتی که اشیای محسوس مانند افراد، مکانها و چیزهایی را که شناسایی و ارزیابی میشوند، نشان میدهند.
دسته بندی ها – متن به دسته ها تفکیک شده است.
برجسته – نهاد چقدر مرتبط است.
Google یک نسخه نمایشی رایگان NLP API دارد که می تواند برای تجزیه و تحلیل نحوه مشاهده و درک متن توسط Google استفاده شود. این به شما امکان می دهد پیشرفت های محتوا را شناسایی کنید.
توصیه هایی در دنیای NLP
NLP همچنین برای بررسی و درک متن لنگر که برای پیوند دادن صفحات استفاده می شود استفاده می شود. بنابراین، اطمینان از مرتبط و آموزنده بودن متن لنگر بیش از هر زمان دیگری مهم است.
اطمینان از اینکه هر صفحه دارای یک جریان طبیعی است، با سرفصل هایی که سلسله مراتب و خوانایی را ارائه می دهند.
پاسخ دادن به سوالی که مقاله در حال پرسش است در اسرع وقت. اطمینان حاصل کنید که کاربران و موتورهای جستجو می توانند اطلاعات کلیدی را بدون تلاش زیاد کشف کنند.
مطمئن شوید که از املا و علائم نگارشی صحیح برای نشان دادن اقتدار و قابل اعتماد استفاده می کنید.
مدل های گوگل
هوش مصنوعی و یادگیری ماشین در بسیاری از محصولات و خدمات Google استفاده می شود. محبوب ترین استفاده از آن در زمینه جستجو، درک زبان و هدف پشت پرس و جوهای جستجو است.
جالب است ببینید که چگونه چیزها در جستجو به دلیل پیشرفت در فناوری مورد استفاده، به لطف مدل ها و الگوریتم های یادگیری ماشین، تکامل یافته اند.
پیش از این، سیستمهای جستجو فقط به دنبال کلمات منطبق بودند، که حتی غلط املایی را در نظر نمیگرفتند. در نهایت، الگوریتم هایی برای یافتن الگوهایی ایجاد شدند که غلط املایی و غلط املایی احتمالی را شناسایی می کردند.
پس از اینکه گوگل در سال 2016 قصد خود را برای تبدیل شدن به اولین شرکت یادگیری ماشینی تایید کرد، چندین سیستم در چند سال گذشته معرفی شده اند.
RankBrain
اولین مورد RankBrain بود که در سال 2015 معرفی شد و به گوگل کمک می کند تا بفهمد کلمات مختلف چگونه با مفاهیم مختلف مرتبط هستند.
این امر به گوگل امکان می دهد تا یک پرس و جو گسترده را انجام دهد و نحوه ارتباط آن با مفاهیم دنیای واقعی را بهتر تعریف کند.
سیستمهای Google از دیدن کلمات استفاده شده در یک پرس و جو در صفحه یاد میگیرند، که سپس میتواند از آنها برای درک عبارات و تطبیق آنها با مفاهیم مرتبط استفاده کند تا بفهمد کاربر چه چیزی را جستجو میکند.
تطبیق عصبی
تطبیق عصبی در سال 2018 راه اندازی شد و در سال 2019 به جستجوی محلی معرفی شد.
این به Google کمک می کند تا با مشاهده محتوای یک صفحه یا یک عبارت جستجو و درک آن در زمینه محتوای صفحه یا پرس و جو، چگونگی ارتباط پرس و جوها با صفحات را درک کند.
اکثر پرس و جوهایی که امروزه انجام می شوند از تطابق عصبی استفاده می کنند و در رتبه بندی استفاده می شود.
BERT
BERT که مخفف عبارت Bidirectional Encoder Representations from Transformers است، در سال 2019 راه اندازی شد و یکی از تاثیرگذارترین سیستم هایی است که گوگل تا به امروز معرفی کرده است.
این سیستم به گوگل این امکان را میدهد تا بفهمد که چگونه ترکیب کلمات معانی و مقاصد مختلف را با بررسی کل توالی کلمات در یک صفحه بیان میکنند.
BERT اکنون در اکثر پرس و جوها استفاده می شود، زیرا به گوگل کمک می کند تا بفهمد کاربر به دنبال چه چیزی است تا بهترین نتایج مربوط به جستجو را نشان دهد.
MUM
MUM که به معنای مدل یکپارچه چند وظیفه ای است، در سال 2021 معرفی شد و برای درک زبان ها و تغییرات در عبارات جستجو استفاده می شود.
LaMBDA
Language Models for Dialog Application یا به اختصار LaMDA جدیدترین مدل است و برای فعال کردن گوگل برای برقراری مکالمات روان و طبیعی استفاده می شود.
این از جدیدترین پیشرفتها برای یافتن الگوها در جملات و همبستگی بین کلمات مختلف برای درک سؤالات ظریف استفاده میکند – و حتی پیشبینی میکند که کدام کلمات احتمالاً بعدی هستند.
Predictive Prefetching
با ترکیب دادههای تاریخی وبسایت در مورد رفتار کاربر با قابلیتهای یادگیری ماشینی، برخی از ابزارها میتوانند حدس بزنند که کاربر احتمالاً به کدام صفحه پیمایش میکند و شروع به واکشی اولیه منابع لازم برای بارگیری صفحه کند.
این به عنوان پیش واکشی پیش بینی شناخته می شود و می تواند عملکرد وب سایت را افزایش دهد.
واکشی پیشبینیکننده میتواند برای سناریوهای دیگر نیز اعمال شود، مانند پیشبینی بخشهایی از محتوا یا ویجتهایی که کاربران به احتمال زیاد با آنها مشاهده یا با آنها تعامل دارند و شخصیسازی تجربه بر اساس آن اطلاعات.
آزمایش
اجرای تست های SEO A/B یکی از موثرترین روش ها برای ارائه تاثیر سئو تغییرات است و توانایی تولید نتایج آماری معنی دار با استفاده از الگوریتم های یادگیری ماشین و شبکه های عصبی امکان پذیر است.
SearchPilot نمونهای از تست SEO A/B است که توسط مدلهای یادگیری ماشین و شبکه عصبی پشتیبانی میشود.
با شروع با یک الگوریتم سطل سازی که از نظر آماری سطل های مشابهی از صفحات کنترل و انواع مختلف برای انجام آزمایش ها ایجاد می کند، یک مدل شبکه عصبی سپس ترافیک مورد انتظار را به صفحاتی که آزمایش روی آنها اجرا می شود پیش بینی می کند.
مدل شبکه عصبی، که برای محاسبه هر و همه تأثیرات خارجی مانند فصلی بودن، فعالیت رقیب، و بهروزرسانی الگوریتم آموزش داده شده است، همچنین ترافیک جستجوی ارگانیک را در صفحات مختلف تجزیه و تحلیل میکند و نحوه عملکرد آنها در برابر گروه کنترل را در طول آزمون شناسایی میکند. .
این همچنین به کاربران امکان می دهد محاسبه کنند که آیا تفاوت در ترافیک از نظر آماری معنی دار است یا خیر.
(سلب مسئولیت: من برای SearchPilot کار می کنم.)
Internal Linking
یادگیری ماشینی از دو طریق می تواند به پیوند داخلی کمک کند:
به روز رسانی لینک های شکسته: یادگیری ماشینی می تواند سایت شما را بخزد تا پیوندهای داخلی شکسته را پیدا کند و سپس آنها را با پیوندی به بهترین صفحه جایگزین جایگزین کند.
پیشنهاد پیوند داخلی مرتبط: این ابزارها می توانند از داده های بزرگ برای پیشنهاد پیوندهای داخلی مرتبط در طول فرآیند ایجاد مقاله و در طول زمان استفاده کنند.
وظیفه پیوند داخلی دیگر ممیزی پیوند داخلی است. این شامل تجزیه و تحلیل تعداد پیوندهای داخلی به یک صفحه، قرار دادن پیوندها همراه با متن لنگر، و عمق خزیدن کلی صفحه است.
طبقهبندی Anchor Text همچنین میتواند برای شناسایی عباراتی که بیشتر در متن جایگزین استفاده میشوند و دستهبندی آنها بر اساس موضوعات و اینکه آیا آنها عبارتهای مارک دار یا غیر مارک هستند، انجام میشود.
شرح تصویر برای متن جایگزین
به عنوان متخصص سئو، ما اهمیت متن جایگزین تصویر را درک می کنیم. آنها دسترسی را برای افرادی که از صفحهخوانها استفاده میکنند بهبود میبخشند و در عین حال به خزندههای موتورهای جستجو کمک میکنند تا محتوای صفحهای را که در آن قرار دادهاند درک کنند.
از مدلهای بینایی زبان میتوان برای نوشتن خودکار تصاویر استفاده کرد، بنابراین محتوایی را ارائه میدهد که میتواند به عنوان متن جایگزین استفاده شود. زیرنویس تصویر برای توصیف آنچه در یک تصویر در یک جمله نشان داده می شود استفاده می شود.
دو مدل برای نوشتن شرح تصاویر استفاده می شود که هر دو به اندازه دیگری مهم هستند. مدل مبتنی بر تصویر با استخراج ویژگی ها از تصویر شروع می شود، در حالی که مدل مبتنی بر زبان آن ویژگی ها را به یک جمله منطقی ترجمه می کند.
نمونه ای از شرح تصاویر در دنیای واقعی چارچوب یادگیری عمیق Pythia است.
سایر وظایف سئو
سایر مقالات ارزش بررسی بر روی استفاده از یادگیری عمیق برای خودکارسازی بهینه سازی برچسب عنوان و طبقه بندی هدف با استفاده از یادگیری عمیق تمرکز دارند.
اگر علاقه مند به استفاده از یادگیری ماشینی در کارهای روزانه سئو هستید، این مقاله توسط لازارینا استوی را حتما بخوانید – و اگر می خواهید با چند اسکریپت فوق العاده جالب بازی کنید، این مجموعه از نوت بوک های Colab از بریتنی مولر بهترین مکان برای شروع است.
در نتیجه
یادگیری ماشین فقط به ChatGPT و BARD محدود نمی شود.
کاربردهای عملی زیادی برای یادگیری ماشین، هم در دنیای واقعی و هم در دنیای سئو وجود دارد – و اینها احتمالاً شروع کار هستند.
و در حالی که آگاهی از سوالات اخلاقی مرتبط با یادگیری ماشین حیاتی است، اما پیامدهای هیجان انگیزی برای آینده سئو دارد.







